Agents: From Inference-Time Scaffolding to Inference-Time Compute
In under three years, LLM-based agents sprinted from useful tools to powerful coding and computer-use systems.
This is a survey of one specific arc: how "reasoning" and
"autonomy" moved from external scaffolding, to imitation learning, to self-improvement -
(first SFT-based, then RL-based), eventually arriving at models that perform these behaviors natively
within their own reasoning trace.
Arc at a glance
1External scaffolding
ReAct, Reflexion, ToT
2Imitation learning
Orca, FireAct
3Self-improvement loops
STaR, ReST-EM (SFT)
4RL optimization
Quiet-STaR, GRPO, R1
From scaffolded behavior to learned reasoning behavior
Autonomy and reasoning through external scaffolding
The progression from passive language models to agentic systems didn’t
happen in one leap. Early progress came from wrapping models in externalized scaffolding:
explicit traces (so the model could “think” in text), interaction loops (so it could
act and observe), evaluators (so it could tell success from failure), and memory (so it could
improve across trials).
ReAct paper introduces an inductive bias: it represents
problem-solving as an explicit Thought -> Action -> Observation loop.
A "thought" in this context is a language step that doesn't change the environment
but updates the agent's working context (you can see illustration in interactive example below),
while an "action" queries or manipulates the environment and returns a new observation.
This scaffold makes long-horizon behavior more reliable because each added thought
(plan, subgoal status, retrace of failed directions) reshapes what the model conditions on next,
and each observation re-anchors the trajectory in external evidence.
A key ReAct insight is that much of the relevant competence already exists in a strong pretrained LLM.
ReAct largely changes how that competence is exercised at inference time by adding structured
state and closed-loop feedback rather than changing the weights.
In the same era, other methods (e.g., Self-Refine, which iteratively generates feedback and
revises a draft) reinforced a similar theme: adding a structured inference-time loop,
whether via environment observations or self-critique, can improve reliability across benchmarks
without additional training. In hindsight, these works were early hints of inference-time scaling.
Interactive Example: ReAct
💬
"What is the attention mechanism?"
↓
💭
Think
↗↘
👁
Observe
LLM decides: loop or stop
⚡
ActLLM picks
↑↓
Environment
searchfetch_papercalculator
✓
Final Answer
Agent Trace
Trace will accumulate here as the agent runs...
Click Next to watch the agent reason, act, observe, and decide when to stop.
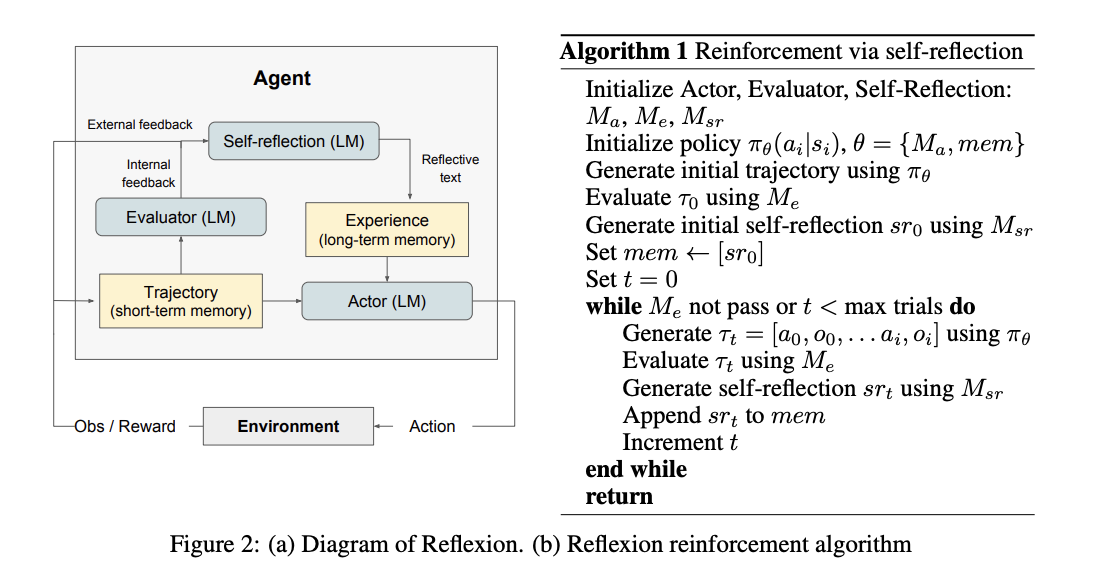
Reflexion paper did not introduce a new type of autonomous agent, rather it introduced
framework for incorporating memory of learned lessons from previous
episodes into an agentic system and hence significantly enhancing capabilities of existing agents.
Essentially, Reflexion sits on top of an existing actor (e.g., one of the agents they used was ReAct)
and augments memory to learn from errors made in previous episodes.
The framework decomposes an LLM agent into three roles repeated over episodes (trials).
The Actor which can be any LLM-based agent (e.g., ReAct) interacts with the environment to produce a trajectory - the ordered record of
a single attempt (actions, observations, and, when using ReAct, intermediate thoughts).
This trajectory is the agent's short-term memory: a working context that is continually
appended. After the episode ends, an Evaluator assigns a pass or fail to the answer Actor produced. Depending on the task,
this evaluator can be programmatic (e.g., unit tests for code, exact-match checks) or LLM-as-a-Judge when semantic judgment is required.
If answer fails Self-Reflection model then reads the trajectory
(and any prior memory) and writes a compact "lesson learned". Reflexion's long-term memory is not the full trajectory. Instead, it stores only these
distilled reflection snippets in a long-term (across-attempts) memory buffer. The next episode starts with a
fresh trajectory, but the Actor is prompted with the recent reflections from long-term episodic memory,
so it can avoid repeating the same mistake and improve across attempts.
Interactive Example: Reflexion
💻
"Return 2nd largest unique element"
↓
🤖
ActorLLM(task + reflections)
↓
🧪
Evaluatorrun_tests(code)
↓
🧐
Self-ReflectLLM(trajectory + results)
↓
Long-term Memory
No reflections yet
↻ retry with memory
✓
Task Complete
Short-term Memory (episode trajectory)
Trajectory builds during each trial...
Trial History
Trial history will appear here...
Click Next to watch the agent learn from failure across trials.
Tree of Thoughts essentially generalizes series of CoT papers by proposing to think about
chain of thoughts as a modular entity which can be split into smaller parts (thoughts),
with new thoughts branching from previous. This framing naturally represents reasoning
as search over a tree, which makes it possible to apply standard search algorithms like
DFS and BFS. The LLM plays two roles here: thought generator (expanding the tree with
new nodes) and evaluator (scoring each thought as sure/likely/impossible to decide
whether to continue or prune).
The interactive example below shows DFS, where the agent explores one branch deeply,
going down to the child with the highest evaluator score at each step. If the evaluation
drops below a threshold, it backtracks - and crucially, the pruned branch’s
thoughts are removed from the model’s context. The next generation is conditioned
only on the parent’s state, so the dead-end reasoning is no longer in the prompt.
One interesting angle is the relationship to MDPs: in some tasks the current state
incorporates all the necessary information to make the next decision (so it is naturally Markov),
while in others the current state is not enough and you essentially need to create a new state by rolling
the whole trajectory (from root to the current node) into the state, hence making it Markov.
So state management in ToT really depends on the task.
On the Game of 24, GPT-4 with standard Chain-of-Thought prompting solved only 4% of tasks,
while ToT with BFS reached 74%.
Interactive Example: Tree of Thoughts - Game of 24 with DFS
Use 4, 9, 10, 13 with +, −, ×, ÷ to make 24
4, 9, 10, 13
4 + 9 = 13left: 10, 13, 13
13 − 9 = 4left: 4, 4, 10
13 − 10 = 3left: 3, 13
13 × 13 = 169left: 10, 169
10 − 4 = 6left: 4, 6
4 × 6 = 24 ✓
DFS Search Log
Search log will appear here...
Click Next to watch DFS explore the tree, evaluate thoughts, and backtrack from dead ends.
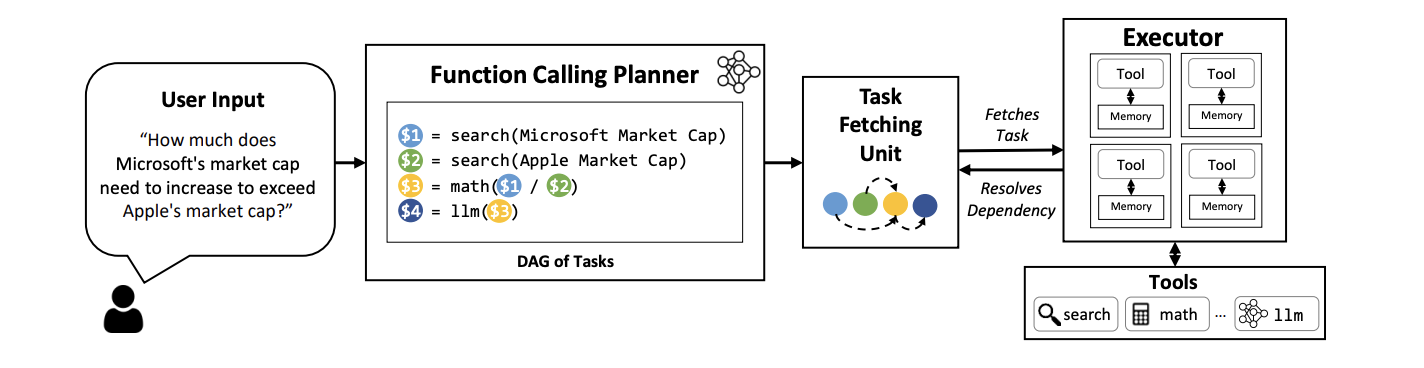
LLM Compiler paper essentially implemented a plan-and-execute pattern with a feedback loop.
At the first stage function calling planner would analyze request and try to create a DAG of tasks that needs to be executed
(tasks themselves might be function calls, subsequent LLM calls etc.) and schedule them in a way that allows
parallel execution of non-dependent tasks. The significance here compared to a simple ReAct loop was toward agent efficiency:
not just choosing the right actions, but choosing the right execution order
to minimize latency. The model controls both what to do and
when to do it. If the execution of some tasks fails, the agent retries and replans.
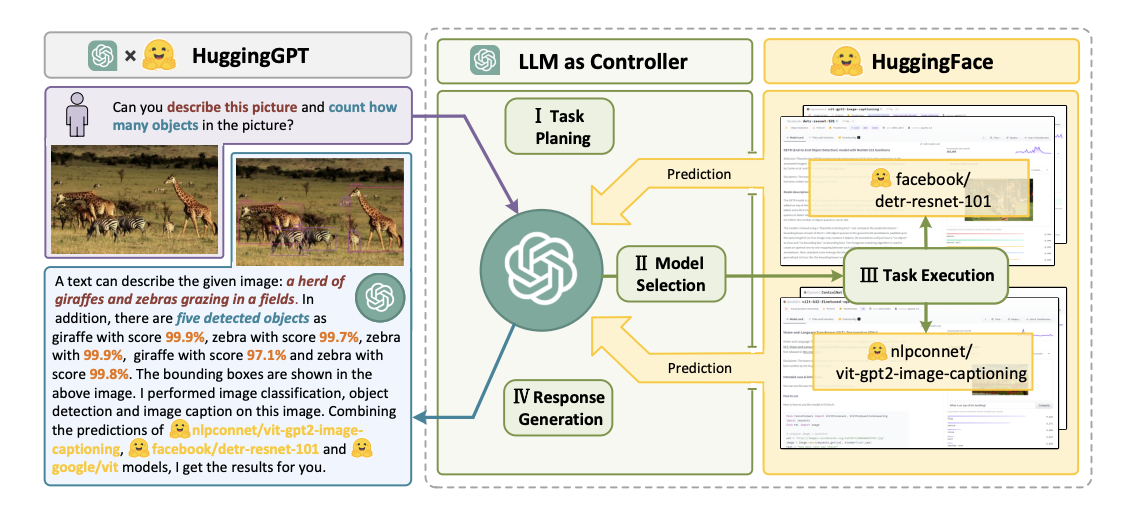
There were many other papers with this plan and execute pattern, one interesting paper applying this pattern to construction of ML
pipelines was HuggingGPT. In this paper the LLM interprets a user’s natural-language request, breaks it down
into actionable subtasks, selects appropriate expert models from Hugging Face for each subtask, runs those models to complete each piece,
and then integrates and summarizes the outputs back to the user.
From scaffold-based to model-based reasoning
Two papers that many people point to as an inspiration for the development of
internalized reasoning:
Few-shot Chain-of-Thought (Wei et al., 2022) showed that adding step-by-step reasoning examples in the prompt
improves performance on reasoning tasks.
Zero-shot Chain-of-Thought (Kojima et al., 2022) showed that just prompting a model with “think step-by-step” was sufficient to elicit
reasoning and improve performance on several tasks.
In combination, these papers showed that models had some latent reasoning capabilities already
and the prompt simply activates them.
Learning to Reason by Imitation
The natural follow-up to the discovery of CoT and the success of harness-based reasoning agents described in the previous section was
imitation learning.
In fact, in the original ReAct paper authors describe experiments with fine-tuning, taking 3,000 trajectories
with correct answers generated by ReAct (with PaLM 540B) and fine-tuning smaller models "to decode trajectories (all thoughts, actions, observations) conditioned on
input questions/claims.". Results on multi-hop reasoning benchmarks like HotPotQA showed significant improvements.
Orca took a similar approach - it distills a teacher's
answer style that includes step-by-step reasoning into a smaller model. Training samples represent triplets:
(system_message, user_query, teacher_response). The system message is specifically crafted with zero-shot CoT or similar prompts to force
the teacher (GPT-4) to produce reasoning traces (e.g. "think step-by-step and justify"), and the paper introduced
diversity of those system messages.
Orca is trained with standard SFT where the Categorical Cross Entropy loss is computed only on the teacher tokens.
So Orca learns the mapping from input = (system + user query) => output = (teacher_reasoning + teacher_answer).
The key result of the paper is that at inference time the model produces reasoning traces by default, without needing the system prompt, even though
during fine-tuning it saw wide diversity of zero-shot CoT like prompts. In fact, authors explicitly state that for some evaluations
they used an empty system message, which also shows that Orca didn't overfit on the CoT-style system prompts because it elicits reasoning even without them.
While Orca reports large improvements on BigBench-Hard, AGIEval and several other benchmarks, they report them
in the no-CoT setting - which is fair as a measure of default behavior, but it doesn’t isolate
the causal effect of explanation-tuning. A more informative ablation would evaluate Vicuna
and Orca under matched CoT-style system prompts (e.g., “think step-by-step”) using the same prompt
template and parsing, so you can separate gains from prompting versus gains from fine-tuning on explanation traces.
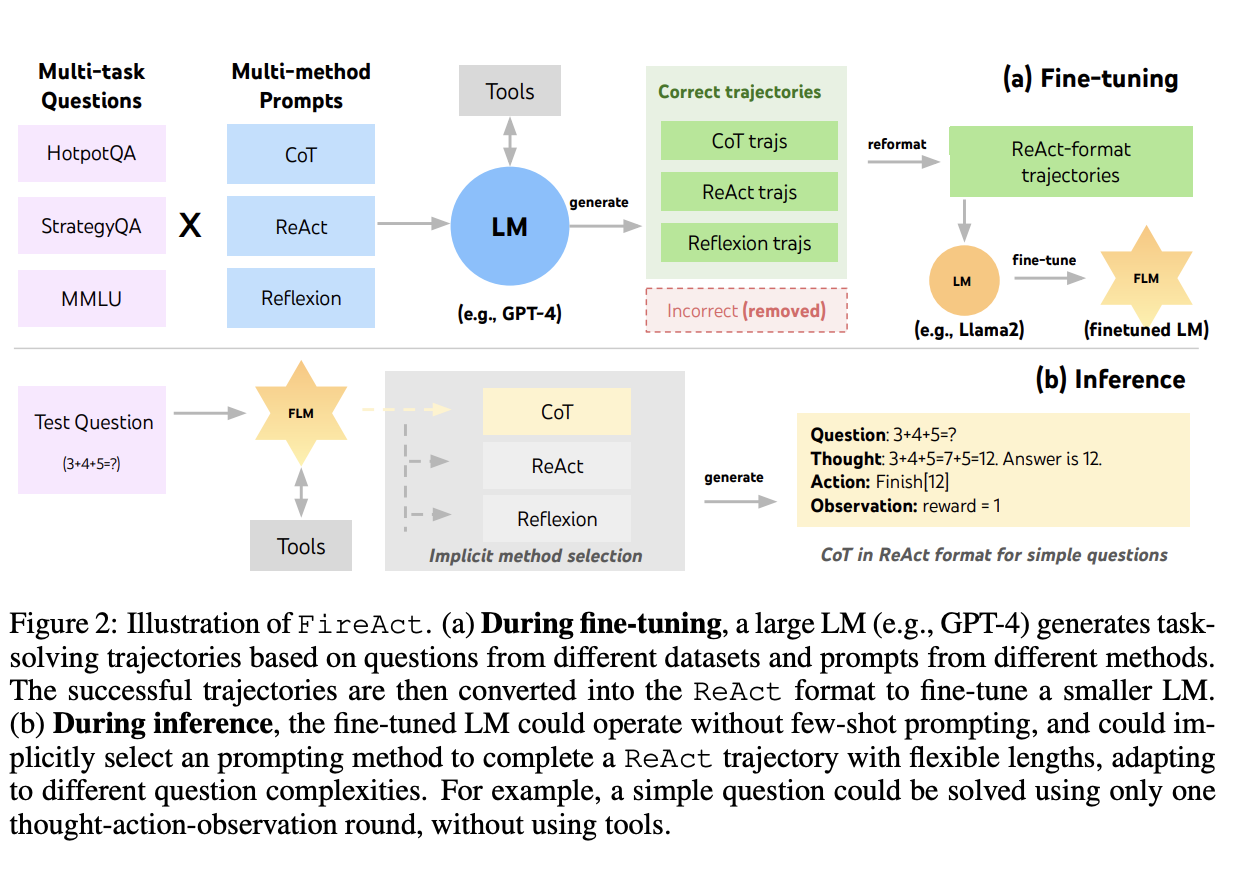
FireAct (Chen et al., 2023) extended this imitation approach to full
agentic trajectories. Rather than distilling from a single teacher
using a single prompting strategy, FireAct generated Think->Act->Observe traces
from multiple models (GPT-4, GPT-3.5) using multiple agent methods (ReAct, CoT, Reflexion-style)
and fine-tuned a smaller model on the combined set. The key finding was that diversity of
source agents matters - the student trained on mixed trajectories generalized better than one
trained on any single agent type, learning to reason and act more flexibly than the individual
strategies it was trained on.
These imitation approaches proved that models could be fine-tuned to replicate the teacher's
reasoning - producing explicit reasoning tokens at inference time, without needing a
scaffold prompt. But this paradigm has no self-improvement loop:
improvement comes from iterating on the scaffolding and teacher setup, which relies on human
engineering rather than computation - in many ways the opposite of
Sutton's bitter lesson.
Learning Through Self-Improvement Loop
STaR (Zelikman et al., 2022) introduced a self-improvement loop that removes the teacher
entirely. The idea: the model generates its own reasoning traces, keeps the ones that lead
to correct answers, and fine-tunes on them. Then repeats. Each iteration produces a better
model that generates better traces in the next round.
The algorithm has one additional clever mechanism: rationalization.
When the model gets a question wrong, STaR gives it a hint (the correct answer) and asks it
to generate a rationale that arrives at that answer. If the rationalized trace is correct,
it gets added to the training set too. This way the model learns not only from problems it
already solves, but also bootstraps from problems it can solve with a hint - gradually
expanding its reasoning capability.
One interesting detail in the paper is that they outline an alternative to rationalization:
generating multiple trajectories at higher temperatures to force diversity, then selecting the
successful ones. However, they found this "substantially increases the likelihood of a
correct answer despite incorrect reasoning". What I find interesting is that for LLMs in
the era when STaR was written, the same is probably true for rationalization - LLM would produce plausibly sounding,
but incorrect or incomplete reasoning for the hinted answer.
Interactive Example: STaR - One Iteration
Task: answer arithmetic word problems using step-by-step reasoning
Example A - Rationale Generation
Q: A store sells 4 apples at $3 each and 2 oranges at $5 each. What is the total?
Prompt to model:few_shot_examples + xi
Rationale r̂i:
4 × $3 = $12 for apples. 2 × $5 = $10 for oranges. Total = $12 + $10 = $22.
Answer ŷi: $22
Check: ŷi = $22 vs yi = $22
✓ match → keep (xi, r̂i, yi)
Example B - Rationale Generation
Q: A train travels 60 mph for 2.5 hours, then 40 mph for 1.5 hours. Total distance?
Check: ŷrati = 210 vs yi = 210
✓ match → keep (xi, r̂rati, yi)
↓
Filter & Combine
↓
Fine-tune M on correct traces
↓
↻ Repeat with improved model
STaR Algorithm Log
Algorithm steps will appear here...
Click Next to step through one iteration of STaR’s self-improvement loop.
Ready
A year after STaR, ReST-EM
(Singh et al., 2023) took a different approach to the same self-improvement idea.
Instead of rationalization approach, they simply sampled many candidate solutions
per problem (32-64), filters for correct outcomes, and fine-tunes on the surviving traces.
The paper was not focused on reasoning specifically - it framed this as a general
self-training method based on expectation-maximization: filtering = expectation step, while maximization step = SFT on filtered set of trajectories.
One detail worth noting: both papers fine-tune from the original base model at
every iteration, not from the previous iteration's checkpoint.1
Both STaR and ReST-EM use SFT as the optimization mechanism, but there is an RL interpretation
hiding behind both. ReST-EM's generate-filter-train loop can be viewed as a REINFORCE-without-baseline
style algorithm: with binary reward, REINFORCE only gets gradient signal from correct trajectories -
which is exactly what ReST-EM's filtering does. However, the major difference is that instead of a single
policy gradient step, ReST-EM performs full SFT on the filtered set.
The STaR paper makes this connection even more explicitly, framing the self-improvement loop
as a policy-gradient style algorithm. Though because rationalizations are generated conditioned on
the correct answer (a hint the model wouldn't have at test time), they are off-policy -
so the algorithm resembles REINFORCE structurally but can't really be considered REINFORCE proper.
One of the subsequent papers that made the use of REINFORCE explicit was
Quiet-STaR
(Zelikman et al., 2024), which used REINFORCE to train hidden thinking tokens.
Around the same time,
DeepSeekMath
(Shao et al., 2024) introduced Group Relative Policy Optimization (GRPO) and
trained reasoning using what is now called RLVR - reinforcement learning from verifiable
rewards.
What made these results striking - and what
DeepSeek-R1
(DeepSeek-AI, 2025) later demonstrated even more dramatically is that
reasoning emerged naturally from the training process itself. In R1-Zero,
the model is trained with RL directly from a base model (no SFT warmup).
The authors report that long chain-of-thought traces and
reflection-like behaviors (including an "aha moment" where the model
pauses to re-check its work) emerged during training,
apparently because such behaviors were instrumentally useful for earning reward,
rather than being explicitly supervised as step-by-step solutions.
This is the approach that scaled, and variations of which are widely used today.
We won't go in-depth on Quiet-STaR, DeepSeekMath, or R1 here - we will try to have
a separate blog post dedicated to them.
Internalized Agentic Behavior: Reasoning and Acting in the Same Trace
In current thinking models, action and reasoning can be performed within
reasoning traces, and many of the functionalities of early agentic systems that relied
on scaffolding are now internalized in the model itself.
To illustrate, consider an extremely simple setup: two plain Python functions -
get_weather and get_city_traffic registered as tools,
and a single user message: "I am heading downtown. What's the weather and
how bad is traffic?" No orchestration loop or scaffolding - the model receives the tools, decides which to call
and in what order inside its own reasoning trace. Once results from a tool call are
returned, reasoning continues based on the environment feedback. In this simple setup
you can see similarities to the plan-and-execute and ReAct patterns from the first
section. It is easy to experiment and see for yourself that backtracking is also natively supported by the model.
Decoded Trace: Reasoning + Tool Use in One Generation
Click Next to watch reasoning and tool use interleave in a single trace.
Ready
You can see in this simple example how all of this works without scaffolding. The model
decides how much to think before acting and whether to act at all. A
ReAct agent always executed the Think -> Act -> Observe cycle because the
scaffold enforced it. A reasoning model might think for twenty steps, realize the answer is
already derivable from context, and never call a tool. Or it might call three tools in quick
succession because its internal reasoning identified a dependency chain.
Conclusion
Scaffolding still exists today - Claude Code, Codex, and many production agents run
inside substantial harnesses. But the role of that scaffolding has shifted. It is less about
forcing multi-step reasoning through an explicit loop - much of that is now handled
by the model itself. Instead, the scaffolding increasingly provides the medium in
which the model operates: tools, file system access, a scratchpad where the model can write
down intermediate thoughts and manage its own context across turns. You see less and less of
the early-agent pattern where the scaffold dictated how to think - it just
provides the environment and lets the model decide.
The improvement comes from the training data getting better each round (more
correct traces, covering harder problems), not from accumulated weight changes.
Resetting to the base model each time keeps the pre-trained knowledge intact and
avoids compounding distribution drift across iterations.
↵