ML Environment Engineering: Building Machines That Build Machines
For many companies, applied ML means building and maintaining dozens or hundreds of specialized models:
a ranking model here, a fraud classifier there, a recommendation system for this surface, a churn predictor
for that one. Most of us in applied ML, myself included, still default to hand-driving each of these
picking features, choosing architectures, tuning hyperparameters, running experiments, interpreting results.
It is satisfying work. But increasingly, it feels like the wrong level of abstraction.
We are at a point where it probably makes sense to think less about building models and more
about building environments in which models get built. Instead of being the scientist who runs
the experiment, you become the person who designs the whole lab. This post is about that shift, why I think
it's coming, and what the
early version
of it looks like in practice.
From model building to environment building
The shift I’m describing is analogous to what happened with software deployment. Engineers
used to manually build, test, and deploy code. Then CI/CD pipelines automated most of that. The
engineers didn’t disappear — they moved up a level. They started designing the pipeline,
writing the tests, defining what “good” looks like. The system did the repetitive execution.
Applied ML is ready for a similar move. Instead of building a model, you build the
environment in which models get built: the evaluation harness, the data contracts,
the experiment tracking, the guardrails that prevent overfitting to your benchmarks. Then you
let an agent — or multiple agents — explore the space of candidate approaches within
that environment.
This isn’t traditional AutoML, which typically means hyperparameter search over a fixed
model class. This is broader: the agent can try different feature engineering strategies, different
model families, different ensembling approaches, different preprocessing pipelines. It operates
at the level of “what would a junior applied scientist try next?” rather than
“what’s the optimal learning rate?”
What makes automation possible
Offline-online metric alignment
This approach doesn’t work everywhere. It works in domains where offline evaluation metrics
have decent directional alignment with online outcomes. Not perfect alignment, but enough that improving your offline
metric reliably moves the online metric in the right direction.
Ranking is a good example: NDCG / MRR / MAP improvements offline tend to translate, at least
directionally, to better conversion rates in online A/B experiments.
Recommendation systems, search relevance, churn prediction - in these domains, the
offline-online gap is often manageable enough that automated iteration on the offline metric
is productive. This isn’t universally true — it varies by product, company,
and how well the eval was designed, but I believe it holds in a meaningful number of
real-world settings.
Where it breaks down is domains where there’s no clear offline proxy for what matters
online. Consumer-facing agents are a good example: did a particular tone, a specific tool
call, or a combination of steps in the agent trace lead to conversion and retention? There’s
no straightforward offline metric for that. Automated iteration in these settings can optimize
the wrong thing very efficiently, which is probably worse than not automating at all.
This is why good offline evals are critical for automation.
The infrastructure you need
Assuming decent metric alignment, the environment needs a few specific components:
Strong evaluation with guardrails. This is the most important piece.
Models under optimization pressure tend to cheat — gaming benchmarks in ways
that resemble human shortcutting. One defense is to never let the agent run evaluation
directly: expose it to an evaluation skill you wrote, so the scoring logic is immutable.
But even that isn’t enough. Over many experiments, the agent will overfit to any
validation set it can see. The solution is a public/private holdout split, exactly like
Kaggle competitions: a public set for fast iteration, a private set the agent never
accesses directly, evaluated only once per experiment after the agent selects its best
candidate. Without this split, the agent hill-climbs on whatever metric you give it.
With it, benchmark gaming becomes much harder.
Experiment tracking and logging. Every model the agent trains, every evaluation
it runs, every approach it tries needs to be logged in a structured way. This serves two purposes:
it gives the human reviewer a clear picture of what was explored - it is essentially the interface
through which the agent communicates its findings and decisions - and it gives the agent itself
a history to reason about (what has been tried, what worked, what plateau has been reached,
and what are unexplored directions).
Full-stack access. In many real-world settings, much of the practical
work isn’t the model itself - it’s the data pipelines, feature stores,
and serving infrastructure around it. Giving the agent access to these through skills
or dedicated toolkits (like
Databricks AI Dev Kit)
lets it iterate on the full stack - data, features, training, serving - so
not just the model. Where this naturally leads is an environment where candidate models
can be deployed, load-tested, and evaluated under realistic inference constraints
(latency budgets, memory limits, traffic patterns) before any human reviews them.
This closes the gap between being good on a benchmark and being a full-stack ML agent that
can go from research ideas to production-ready models.
The automated ML agent
To make this concrete, I’ve been building a
demo template
for autonomous ML experimentation using Cursor AI agents. A small agent swarm
explores different research directions concurrently, logs everything to MLflow,
and communicates findings through a shared knowledge base on main.
mainknowledge base
research_directions/mlruns/src/
reads historymerges results
☻Human
steers direction, reviews, stops
↔
◆Orchestrator
manages pool, never trains
launches
launches
launches
1Subagent
exp/deeper-trees
read history on main
research + EDA
announce direction
train + log
pick best candidate
2Subagent
exp/feature-interactions
read history on main
research + EDA
announce direction
train + log
pick best candidate
3Subagent
exp/neural-net
read history on main
research + EDA
announce direction
train + log
pick best candidate
Public eval
agent scores freely
Private eval
one-shot, score hidden
Merge to main
results + learnings
The orchestrator launches research agents
The orchestrator manages a rolling pool of up to 3 concurrent
subagents. It never trains models itself - it launches agents, monitors their
progress, and decides whether to continue or stop. Between completions it
checks in with the human: keep going, change direction, or stop.
Each subagent starts by reading past experiments and learnings
on main, then announces its research direction by writing a separate file to
research_directions/. From there it works freely on an experiment
branch - EDA, feature engineering, model training, whatever it decides. When
done, it merges results and learnings back to main; the full
experimentation code stays on the branch for reference.
Both the orchestrator and the subagents are guided by skills:
the orchestration skill controls launch/monitor/stop decisions,
while the experiment-running and experiment-submission skills
govern how subagents explore, merge and run evaluation with guardrails
to prevent model from cheating, log data with MLflow observability layer.
MLflow tracks all experiment data
Every run logs hyperparameters, per-step training/validation metrics,
and the trained model as an artifact.
Each run carries structured metadata: direction_rationale
(why this approach), run_rationale (why this config), and
run_analysis (what happened and why).
Private evaluation scores are logged to the best run from each direction.
Only results merge to main
Training code, predictions, and model files stay on the branch —
committed there as a complete archive.
Only mlruns/ and research_directions/ merge
to main.
Branches are never deleted — they serve as archives of everything
that produced the results.
Evaluation: public/private split
Agents have file system access. If targets lived in the same CSV as features,
nothing would stop an agent from reading the answer column directly - and under
optimization pressure, this does happen (especially with less powerful models).
Isolating target files (*_y.csv) and gating access through
evaluation scripts creates a hard boundary.
Public validation — agents use freely during research.
evaluate_public() drives all experiment decisions.
Private validation — scored once per direction at
submission time via submit.py. The agent never reads the private
targets directly.
Public-private gap is the signal — if the gap is large,
the agent has overfit the public split. This is the primary failure mode when an
autonomous agent optimizes iteratively, and the split is designed to catch it.
What we got
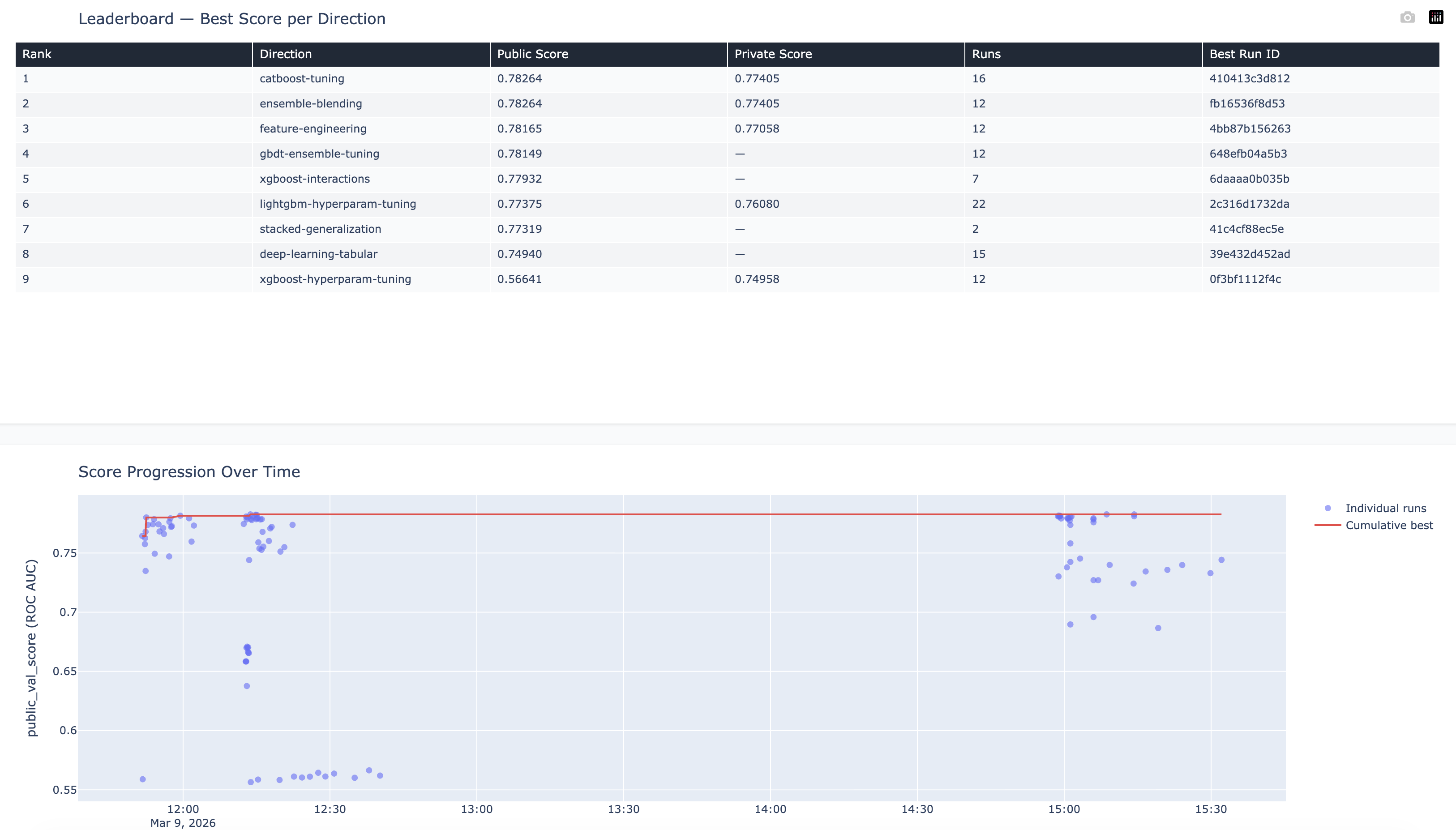
To test this, we generated a synthetic binary-classification dataset where according to Codex
Bayes-optimal AUC shouldbe around 0.784.
We pointed the agent swarm at it and let it run. In a few hours it explored
9 research directions, logged 110 MLflow runs, and tried everything from gradient-boosted
trees to neural nets to stacked ensembles - all autonomously.
The best results: 0.783 public and 0.774 private - came from both a
tuned CatBoost and an ensemble blend, both very close to Bayes Optimal AUC.
The small public/private gap confirms the agent wasn't overfitting the
benchmark. The score progression chart below shows the typical pattern: fast
early gains followed by a long plateau where incremental directions yield
diminishing returns.
What can be improved
Concurrency at scale. Currently each agent merges its own
results with rebase-and-retry. This works for ~3 agents but breaks beyond ~5.
Serializing all writes through the orchestrator would fix it.
Shared code across agents. Agents work in isolation on their
branches. A src/shared/ directory on main where agents
promote battle-tested utilities would let the next agent reuse what the
previous one built.
Richer inter-agent communication. Currently agents share
findings through free-form markdown. Structured metadata per direction
(e.g., features tried, best AUC, failure modes) would let agents make
more informed choices instead of re-discovering what a previous agent
already learned.
What’s next
What we built is a first version (the
full code is on GitHub). There are natural next steps:
deeper integration with observability tooling, full-stack access
to data and serving infrastructure, and the agent improvements
outlined in the previous section.
The human role. In this setup, the applied ML scientist doesn’t
disappear. The role shifts. You spend less time running experiments and more time on the
things that matter most: designing evaluation metrics that actually correlate with business
outcomes, identifying new signal sources, reviewing what the agent tried and spotting the
creative leaps it missed, and deciding when the offline-online alignment is trustworthy
enough to automate and when it isn’t.
In domains where offline metrics have decent alignment with online outcomes, I believe a
significant fraction of model research and iteration can be automated with current LLMs.
As models improve, so does the case for automation.
The investment shifts from building models to building the environments in which models get built.